近日我校多篇论文被人工智能与计算机视觉领域的CCF A类顶级会议CVPR 2023录用,彰显了我校在科研和学生学术创新能力培养方面的成效。
颜成钢教授团队以杭电为第一单位的论文“Gaussian Label Distribution Learning for Spherical Object Detection”被计算机视觉领域的CCF A类顶级会议CVPR 2023主会(main conference)接收,该论文的合作单位有中国科学院计算技术研究所。论文第一作者是我校“智能信息处理实验室”(HDU IIPLab)的博士研究生徐杭。
全景视觉数据是通过全景数据采集设备采集得到的全景图像或全景视频,它包含了空间中全方位360度的视觉信息,具有“视野全、可交互、沉浸感强”的特点。这使得其在很多领域都得到了很好的应用,如虚拟现实、机器人、视频监控等。本研究工作专注于全景视觉目标检测领域,提出了一种简单有效的回归损失函数来提升全景视觉目标检测算法的性能。具体来说,在训练阶段,首先将预测的球面矩形框和真实的球面矩形框的切面转换成高斯分布。然后,使用K-L散度来度量两个分布之间的距离。在测试阶段,直接从已训练模型中获得球形包围框的输出,因此网络的推理时间保持不变。整个方法的框架如下所示:
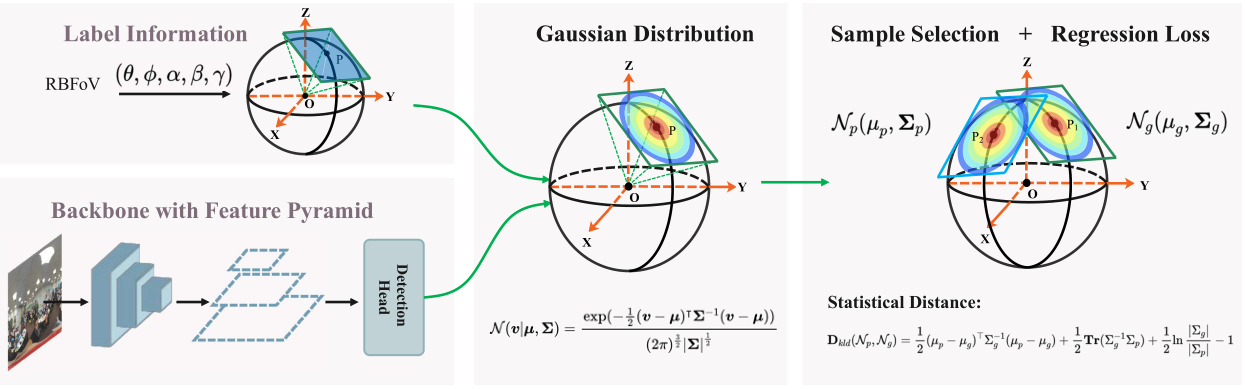
图1 训练模型框架
论文“Prompting Large Language Models with Answer Heuristics for Knowledge-based Visual Question Answering”研究了如何利用“外部知识”进行跨媒体推理的挑战性问题。GPT-3、ChatGPT等大规模语言模型内部蕴含了丰富的知识,如何将其作为隐式知识库来进行推理是跨媒体研究的挑战性问题。本文提出的Prophet方法提出一种 “答案启发”的通用跨媒体推理框架,通过在大模型上游引入一个可学习的任务相关视觉问答小模型,来更好地激发大模型的潜力。该论文第一作者为媒体智能实验室硕士研究生邵镇炜同学,通讯作者为计算机学院余宙教授。邵镇炜同学患有“进行性脊肌萎缩症”,肢体一级残疾,没有生活自理能力,生活和学习需要母亲全程照顾。他常年坚持与病魔抗争,同轮椅为伴,克服因身体缺陷带来的种种不便,并努力追求卓越。2017年以644分的成绩被杭州电子科技大学计算机科学与技术专业录取,大学期间获得2018年中国大学生自强之星、2020年度国家奖学金和浙江省优秀毕业生等荣誉。2021年通过研究生推免的方式加入媒体智能实验室攻读硕士研究生。
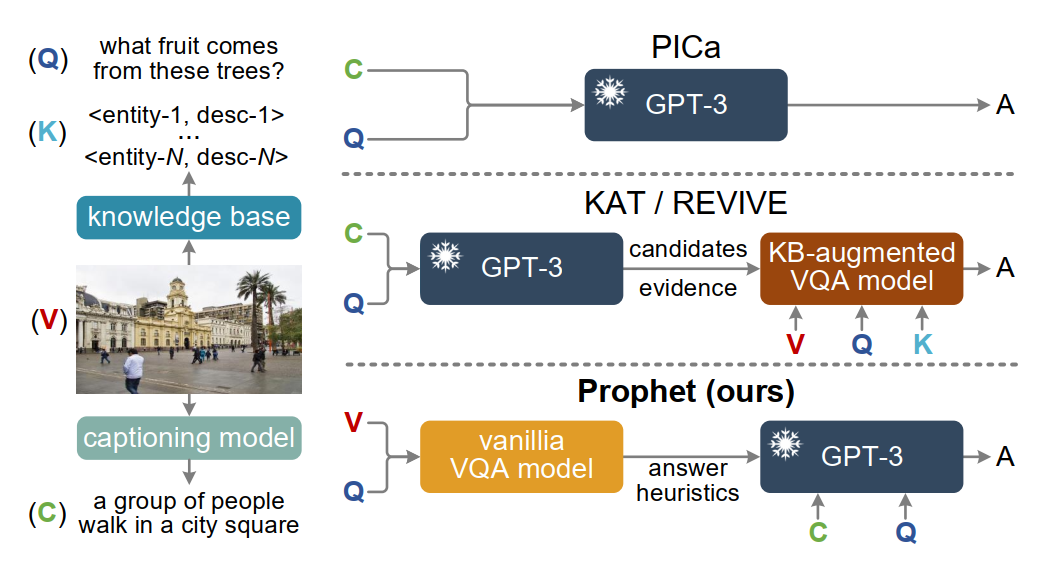
图2 通用跨媒体推理框架
论文 "Masked and Adaptive Transformer for Exemplar Based Image Translation"提出了一种新颖的基于示例的图像翻译框架,主要关注跨域间建立准确的语义对应关系,以学得示例风格图像生成。该工作提出了 “masked and adaptive transformer” 结构来学习对应关系以执行上下文感知的特征增强。在对比学习约束和全局风格注入的引导下,可生成高质量风格图像。该论文第一作者为计算机学院智能可视建模与仿真实验室(iGame-Lab)2021级硕士研究生蒋畅,通讯作者为高飞副教授,论文的合作者包括硕士生马彪、林裕浩,西安电子科技大学王楠楠教授和杭电iGame实验室负责人徐岗教授。
论文"ANetQA: A Large-scale Benchmark for Fine-grained Compositional Reasoning over Untrimmed Videos"构建了目前最大的面向复杂长视频的问答数据集,通过人工标注“细粒度”视频场景图,在1万个长视频上自动生成了14亿问答样本,过滤平衡后最终形成1300万样本,比现有最大的视频问答数据集(斯坦福大学的AGQA)大一个数量级,在问答细粒度方面优势明显。论文第一作者为余宙教授,通讯作者为俞俊教授,硕士研究生郑力祥同学参与了本文的主要工作。

图3 ANetQA框架

图4 Masked and Adaptive Transformer图像翻译效果图
论文“Trajectory-Aware Body Interaction Transformer for Multi-Person Pose Forecasting”以多人动作预测为研究方向。该论文为人文艺术与数字媒体学院智能媒体计算研究所最新研究成果,论文第一作者为硕士生彭小刚,第二作者为硕士生毛思远,通讯作者为吴子朝副教授。多人三维人体姿态(运动)预测在计算机视觉和人工智能领域都有着巨大的应用价值,例如人机交互,无人驾驶,智能监控和虚拟现实等,其解决的任务是根据观察到的一段运动序列去尽可能准确地预测未来的姿态变化和运动轨迹。现有的大部分研究方法基本都基于单人姿态预测,没有考虑人与人之间的复杂交互影响,如下图5所示。此外基于单人预测的方法主要关注如何建模人体的局部姿态运动而忽略了在三维环境中的全局位置变化。近年来,虽然逐渐出现了一些多人姿态预测的工作来解决上述问题,但这些方法只简单将人体姿态序列表征成时序序列来建模人体之间的运动相关性,没有更加细粒度地去建模人体之间的身体部位交互。
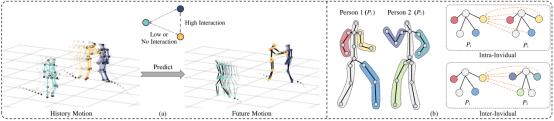
图5. (a) 复杂场景下的多人运动交互,其交互程度有高有低。(b) 关于身体部位交互的建模思路。
因此,研究团队提出一个基于轨迹感知的身体互动Transformer模型去有效建模多人之间的身体部位互动。为了给Transfomer模型输入更有效的数据,我们先引入一个时序部位划分模块,将每个人的姿态运动序列按照身体部位进行划分并把所有人划分好的序列拼接成一个整体,称作多人身体部位序列(MPBP) 。 该序列包括了多人的时序和身体部位信息。 我们的方法在相关数据集的短期 (0.2 —1.0s) 和长期 (1.0—3.0s) 预测任务上都表现出最佳的性能。
CVPR(Computer Vision and Pattern Recognition)是人工智能与计算机视觉领域最高级别的国际顶级学术会议,也是中国计算机学会(CCF)推荐的A类国际学术会议,每年六月召开一次。会议于6月18日-22日在加拿大温哥华召开,今年CVPR共收到了创纪录的9155篇投稿论文,录用2360篇论文,录用率约为25.78%。